Architecture
The figure below shows the high-level architecture of the system.
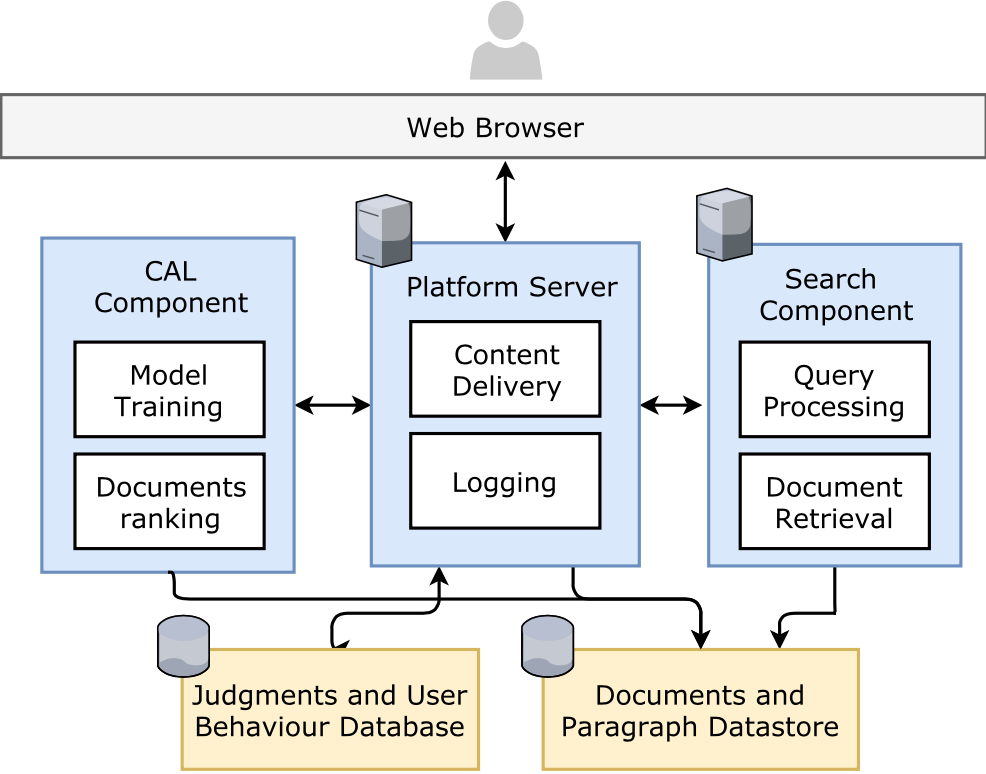
Figure 1: Platform server (i.e. HiCAL-web) responsible for displaying content and communicating requests and responses between components. CAL component (i.e. HiCAL-engine) responsible for training and ranking documents. The Search component is a query-based search engine responsible for retrieving document and ranking documents.
Documentation
Click for more details.
HiCAL-web
The details below are for setting up HiCAL-web (no docker).
Setting up
The system requires a database for storing document judgments, user profiles and topics.
Install postgres and run it, make sure you create a db called HiCAL, or whatever you have set in settings (config/settings/base.py).
To create a db, use this command:
$ createdb HiCAL Create a python3 virtual env, and pip install everything in requirements/base.txt:
$ pip install -r requirements/base.txtIf you are running it locally, you might also want to install everything in requirements/local.txt:
$ pip install -r requirements/local.txt
Your local db is initially empty, and you will need to create the tables according to the models.
To do this, run python manage.py makemigrations and then python manage.py migrate.
For running a uwsgi instance, uwsgi --socket 127.0.0.1:8001 --module config.wsgi --master --process 2 --threads 4
To run locally, run python manage.py runserver
This will start the web server running in the default port 8000. You can access the server by going to http://localhost:8000/.
Setting Up Your Users
Each document judgments is associated with a user profile.
To create a normal user account, just go to Sign Up and fill out the form.
To create an superuser account, use this command:
$ python manage.py createsuperuserFor convenience, you can keep your normal user logged in on Chrome and your superuser logged in on Firefox (or similar), so that you can see how the site behaves for both kinds of users. A superuser can access the platform's admin page by going to /admin (e.g. http://localhost:8000/admin ) or whatever is set in the settings.
Configuring Signup Form
users.models.User contains the custom user model that you can modify to your need. allauth.forms.SignupForm is a custom signup form that you can change to include extra information that will be saved in the user model.
Registration and account management is done using django-allauth.
Component Settings
Communication from and to the component are done through http requests.
Make sure you update the IPs for each component in the config/settings/base.py file.
# HiCAL COMPONENTS IPS *REQUIRED*
# ------------------------------------------------------------------------------
CAL_SERVER_IP = '127.0.0.0'
CAL_SERVER_PORT = '9001' # The port for CAL engine
SEARCH_SERVER_IP = '127.0.0.0'
SEARCH_SERVER_PORT = '80'
DOCUMENTS_URL = '127.0.0.0:9000/doc'
PARA_URL = '127.0.0.0:9000/para'
Integrating Search
Once you have a search engine server running, make sure you update the SEARCH_SERVER_IP and SEARCH_SERVER_PORT in config/settings/base.py.
You also need to update the url variable in the method get_documents in interfaces/SearchEngine/functions.py.
The get_documents method will send a GET request to the url of the search engine.
The parameters of the request are:
- 'start': Integer - Start from rank (keep 0 if you don't know).
- 'numdisplay': Integer - The number of SERP items to return.
- 'query': String - The query to submit to the search engine.
You can change the request as you would like. Update the get_documents to parse the response. Make sure the method returns the following:
result: A list of documents, where each document is composed of
{
"rank": rank, # rank of document
"docno": docno, # doc id
"title": title, # Title of SERP item
"snippet": snippet # Snippet of SERP item
}
doc_ids: A list of document ids in the same order as appeared in result
time_taken: str of the time taken to complete the search request
Example
Suppose the response from the search server (using indri) is an XML of the following format:
<search-response>
<raw-query>foobar</raw-query>
<total-time>0.17908906936646</total-time>
<indri-query>foobar</indri-query>
<indri-sentence-query>#combine[sentence]( foobar )</indri-sentence-query>
<results>
<result>
<rank>1</rank>
<score>-8.00303</score>
<url/>
<docno>774090</docno>
<document-id>1055435</document-id>
<title>
What Goes On?; Don't Speak Unix? Oh? Try http:www.fooledyou
</title>
<snippet>
Purists would say, "lower-case aich tee tee pee colon forward slash forward slash double you double you double you dot <strong>foobar</strong> dot com," and might add that the letters signify a type of server computer that recognizes data transfers based on the hypertext transport protocol, followed by the branches of the specific data directories where Web pages can be found. Whew!
</snippet>
</result>
</results>
</search-response>
Here is an example of what the file interfaces/SearchEngine/functions.py can look like.
from collections import OrderedDict
from config.settings.base import SEARCH_SERVER_IP
from config.settings.base import SEARCH_SERVER_PORT
import urllib.parse
import httplib2
import xmltodict
def get_documents(query, start=0, numdisplay=20):
"""
:param query: The query to submit
:param start: Start from
:param numdisplay: Number of documents to return
:return:
result: A list of documents, where each document is composed of
{
"rank": rank, # rank of document
"docno": docno, # doc id
"title": title, # Title of SERP item
"snippet": snippet # Snippet of SERP item
}
doc_ids: A list of document ids in the same order as appeared in result
time_taken: str of the time taken to complete the search request
"""
h = httplib2.Http()
url = "http://{}:{}/websearchapi/search.php?{}" # Update this url to whatever your search engine supports
parameters = {'start': start, 'numdisplay': numdisplay, 'query': query}
parameters = urllib.parse.urlencode(parameters)
resp, content = h.request(url.format(SEARCH_SERVER_IP,
SEARCH_SERVER_PORT,
parameters),
method="GET")
if resp and resp.get("status") == "200":
xmlDict = xmltodict.parse(content)
try:
xmlResult = xmlDict['search-response']['results']['result']
except TypeError:
return None, None, None
doc_ids = []
result = OrderedDict()
if not isinstance(xmlResult, list):
xmlResult = [xmlResult]
for doc in xmlResult:
docno = doc["docno"].zfill(7)
parsed_doc = {
"rank": doc["rank"],
"docno": docno,
"title": doc["title"],
"snippet": doc["snippet"]
}
result[docno] = parsed_doc
doc_ids.append(docno)
return result, doc_ids, xmlDict['search-response']['total-time']
return None, None, None
Logging
We use python’s built in logging module for system and analytics logging. You can configure logging from the project settings in settings/base.py.
The repo currently has one logging handle. Logs are saved in logs/web.log.
Check config/settings/base.py for more logging configurations.
Using the logger
Once you have configured your logger, you can start placing logging calls into your code. This is very simple to do. Here’s an example:
import logging
logger = logging.getLogger(__name__)
class JudgmentAJAXView(views.CsrfExemptMixin, views.LoginRequiredMixin,
views.JsonRequestResponseMixin,
generic.View):
# some code
...
# log message
log_message = {
"user": self.request.user.username,
"client_time": client_time,
# ...
}
}
# log message
logger.info("{}".format(json.dumps(log_message)))
We suggest you follow a simple logging style that you can easily parse and understand. Place logging message where ever you need to log/track changes in the systems or user behaviour.
Components
Our system currently supports two retrieval components, CAL and Search. All components in the architecture are stand-alone and interact with each other via HTTP API calls. You can also add your own component if you wish.
Adding a component
Let’s go through an example of adding a new component. For simplicity, the component will simply return a list of predefine documents that need to be judged. The component will allow user to access and judge these documents in the order they are define. We’ll call this component Iterative.
Let’s add a new app in our project by running this command:
$ python manage.py createapp iterativeThis will create a folder with all the files we need. You might need to move the directory. Make sure the newly created app is in the right directory. It should be in /HiCAL.
Let’s add the new app to our settings file so that our server is aware of it. You can do this by going to config/settings/base.py file and adding HiCAL.iterative to LOCAL_APPS:
# Apps specific for this project go here.
LOCAL_APPS = [
# custom users app
...
'hical.iterative',
]
Now add a specific url for the app in config/urls.py:
urlpatterns = [
...
# add this
url(r'^iterative/', include('hical.iterative.urls', namespace='iterative')),
]
and create a new urls.py file under the iterative app directory:
from django.conf.urls import url
from hical.iterative import views
urlpatterns = [
url(r'^$', views.HomePageView.as_view(), name='main'),
# Ajax views
url(r'^post_log/$', views.MessageAJAXView.as_view(), name='post_log_msg'),
url(r'^get_docs/$', views.DocAJAXView.as_view(), name='get_docs'),
]
This will allow access to the component from the url /iterative/
We will use get_docs/ url pattern to link to our view DocAJAXView, which will be responsible for getting the documents to judge. Please look at iterative/views.py for more details on what these views do.
Let’s look at DocAJAXView view as an example:
from interfaces.DocumentSnippetEngine import functions as DocEngine
from interfaces.Iterative import functions as IterativeEngine
class DocAJAXView(views.CsrfExemptMixin, views.LoginRequiredMixin,
views.JsonRequestResponseMixin,
views.AjaxResponseMixin, generic.View):
"""
View to get a list of documents to judge
"""
require_json = False
def render_timeout_request_response(self, error_dict=None):
if error_dict is None:
error_dict = self.error_response_dict
json_context = json.dumps(
error_dict,
cls=self.json_encoder_class,
**self.get_json_dumps_kwargs()
).encode('utf-8')
return HttpResponse(
json_context, content_type=self.get_content_type(), status=502)
def get_ajax(self, request, *args, **kwargs):
try:
current_task = self.request.user.current_task
docs_ids = IterativeEngine.get_documents(current_task.topic.number)
docs_ids = helpers.remove_judged_docs(docs_ids,
self.request.user,
current_task)
documents = DocEngine.get_documents(docs_ids, query=None)
return self.render_json_response(documents)
except TimeoutError:
error_dict = {u"message": u"Timeout error. Please check status of servers."}
return self.render_timeout_request_response(error_dict)
The method get_ajax will be called from our template to retrieve a list of documents. The variable docs_ids contains the list of documents ids that we need to retrieve their content. We put all functions associated with the component retrieval in /interfaces directory.
The variable documents will contain a list of documents with their content, in the following format:
[
{
'doc_id': "012345",
'title': "Document Title",
'content': "Body of document",
'date': "Date of document"
},
...
]
documents will be passed as context to our template, and loaded in the browser.
The HTML associated is under iterative/templates/iterative/iterative.html. The HomePageView view, which the url pattern /iterative/^ is pointing to, will render this page. If you look at the HomePageView view, you will see that template_name = 'iterative/iterative.html'.
You can modify the iterative.html file as you like. The iterative.html page will call iterative:get_docs url once the page is loaded. You can customize the behaviour by modifying the javascript code in iterative.html to meet your needs.
The judgment buttons in the interface will call the send_judgment() function, which will send a call to the url judgment:post_judgment in judgments/url.py and run the view JudgmentAJAXView that will save the document's judgment to the database. If you would like to include more information to be saved with each judgment, you can modify the send_judgment() in iterative.html. You will also need to modify the database model, Judgement, associated with each judgment instance. The Judgement class is located in judgment/models.py.
CAL and Search
Both components follow a similar pattern as the Iterative component described above. The difference is that both are running separately. Communication to and from each component (e.g. getting the documents we need to judge) is done through HTTP calls. The IPs for each component must be set in config/settings/base.py. Take a look at the methods used to communicate with components (found in /interfaces/) for further details.
The HTML associated with each component is found under the templates folder under the component directory.
HiCAL engine
Requirements
- libfcgi
- libarchive
- g++
- make
- spawn-fcgi (to run
bmi_fcgi)
Command Line Tool
$ make bmi_cli
$ ./bmi_cli --help
Command line flag options:
--help Show Help
--async-mode Enable greedy async mode for classifier and rescorer,
overrides --judgment-per-iteration and --num-iterations
--df Path of the file with list of terms and their document
frequencies. The file contains space-separated word and
df on every line. Specify only when df information is
not encoded in the document features file.
--jobs Number of concurrent jobs (topics)
--threads Number of threads to use for scoring
--doc-features Path of the file with list of document features
--para-features Path of the file with list of paragraph features (BMI_PARA)
--qrel Qrel file to use for judgment
--max-effort Set max effort (number of judgments)
--max-effort-factor Set max effort as a factor of recall
--num-iterations Set max number of refresh iterations
--training-iterations Set number of training iterations
--judgments-per-iteration Number of docs to judge per iteration (-1 for BMI default)
--query Path of the file with queries (one seed per line; each
line is <topic_id> <rel> <string>; can have multiple seeds per topic)
--judgment-logpath Path to log judgments. Specify a directory within which
topic-specific logs will be generated.
--mode Set strategy: (default) BMI_DOC, BMI_PARA, BMI_PARTIAL_RANKING,
BMI_ONLINE_LEARNING, BMI_PRECISION_DELAY, BMI_RECENCY_WEIGHTING, BMI_FORGET
... (Strategy specific arguments truncated)
- The document frequency data is encoded within the document features bin file.
--dfshouldn't be used unless you are using the old document feature format.
Corpus Parser
This tool generates document features of a given corpus.
The tool takes as input an archived corpus tar.gz. Each file in the corpus is treated
as a separate document with the name of the file (excluding the directories) as its ID.
The files are processed as plaintext document. This gives users freedom to clean and
form corpuses in different ways. In order to use the BMI_PARA mode in the main tool,
the user needs to split each document such that each new document is a single paragraph.
The name of these paragraph files should be <doc-id>.<para-id> (this is used by the tool
to get the parent document for a given paragraph). For this reason, avoid using the character . in
the <doc-id>.
--type as svmlight is not used by the main tool and should be used for debugging purposes.
--out-df only works when --type is svmlight.
The bin output format begins with the document frequency data followed by the document feature
data. The document frequency data begins with a uint32_t specifying the number of dfreq records which follow.
Each dfreq record begins with a null terminated string (word) followed by a uint32_t document frequency.
The document feature data begins with a uint32_t specifying the number of dfeat records which follow.
Each dfeat record begins with a null terminated string (document ID) followed by a feature_list. feature_list
begins with a uint32_t specifying the number of feature_pair which follow. Each feature_pair
is a uint32_t feature ID followed by a float feature weight.
$ make corpus_parser
$ ./corpus_parser --help
Command line flag options:
--help Show Help
--in Input corpus archive
--out Output feature file
--out-df Output document frequency file
--type Output file format: bin (default) or svmlight
FastCGI based web server
$ make bmi_fcgi
$ ./bmi_fcgi --help
Command line flag options:
--df Path of the file with list of terms and their document frequencies
--doc-features Path of the file with list of document features
--help Show Help
--para-features Path of the file with list of paragraph features
--threads Number of threads to use for scoring
fcgi libraries needs to be present in the system. bmi_fcgi uses libfcgi to communicate
with any FastCGI capable web server like nginx. bmi_fcgi only supports modes BMI and BMI_PARA.
Install spawn-fcgi in your system and run
$ spawn-fcgi -p 8002 -n -- bmi_fcgi --doc-features /path/to/doc/features --df /path/to/df
You can interact with the bmi_fcgi server through the HTTP API or the python bindings in api.py.
HTTP API Spec
Begin a session
POST /begin
Data Params:
session_id=[string]
seed_query=[string]
async=[bool]
mode=[para,doc]
seed_judgments=doc1:rel1,doc2:rel2
judgments_per_iteration=[-1 or positive integer]
Success Response:
Code: 200
Content: {'session-id': [string]}
Error Response:
Code: 400
Content: {'error': 'session already exists'}
The server can run multiple sessions each of which are identified by a unique sesion_id.
The seed_query is the initial relevant string used for training. async determines if
the server should wait to respond while refreshing. If async is set to false, the server
immediately returns the next document to judge from the old ranklist while the refresh is
ongoing in the background. mode sets whether to judge on paragraphs or documents.
seed_documents can be used to initialize the session with some pre-determined judgments.
It can also be used to restores states of the sessions when restarting the bmi server.
Use positive integer for relevant and negative integer (or zero) for non-relevant.
Get document to judge
GET /get_docs
URL Params:
session_id=[string]
max_count=[int]
Success Response:
Code: 200
Content: {'session-id': [string], 'docs': ["doc-1001", "doc-1002", "doc-1010"]}
Error Response:
Code: 404
Content: {'error': 'session not found'}
Submit Judgment
POST /judge
Data Params:
session_id=[string]
doc_id=[string]
rel=[-1,1]
Success Response:
Code: 200
Content: {'session-id': 'xyz', 'docs': ["doc-1001", "doc-1002", "doc-1010"]}
Error Response:
Code: 404
Content: {'error': 'session not found'}
Code: 404
Content: {'error': 'doc not found'}
Code: 400
Content: {'error': 'invalid judgment'}
The docs field in the success response provides next documents to be judged.
This is to save an additional call to /get_docs. If async is set to false and
the judgement triggers a refresh, the server will finish the refresh before responding.
Get Full Ranklist
GET /get_ranklist
URL Params:
session_id=[string]
Success Response:
Code: 200
Content (text/plain): newline separated document ids with their scores ordered
from highest to lowest
Error Response:
Code: 404
Content: {'error': 'session not found'}
Returns full ranklist based on the classifier from the last refresh.
Delete a session
DELETE /delete_session
Data Params:
session_id: [string]
Success Response:
Code: 200
Content: {'session-id': [string]}
Error Response:
Code: 404
Content: {'error': 'session not found'}