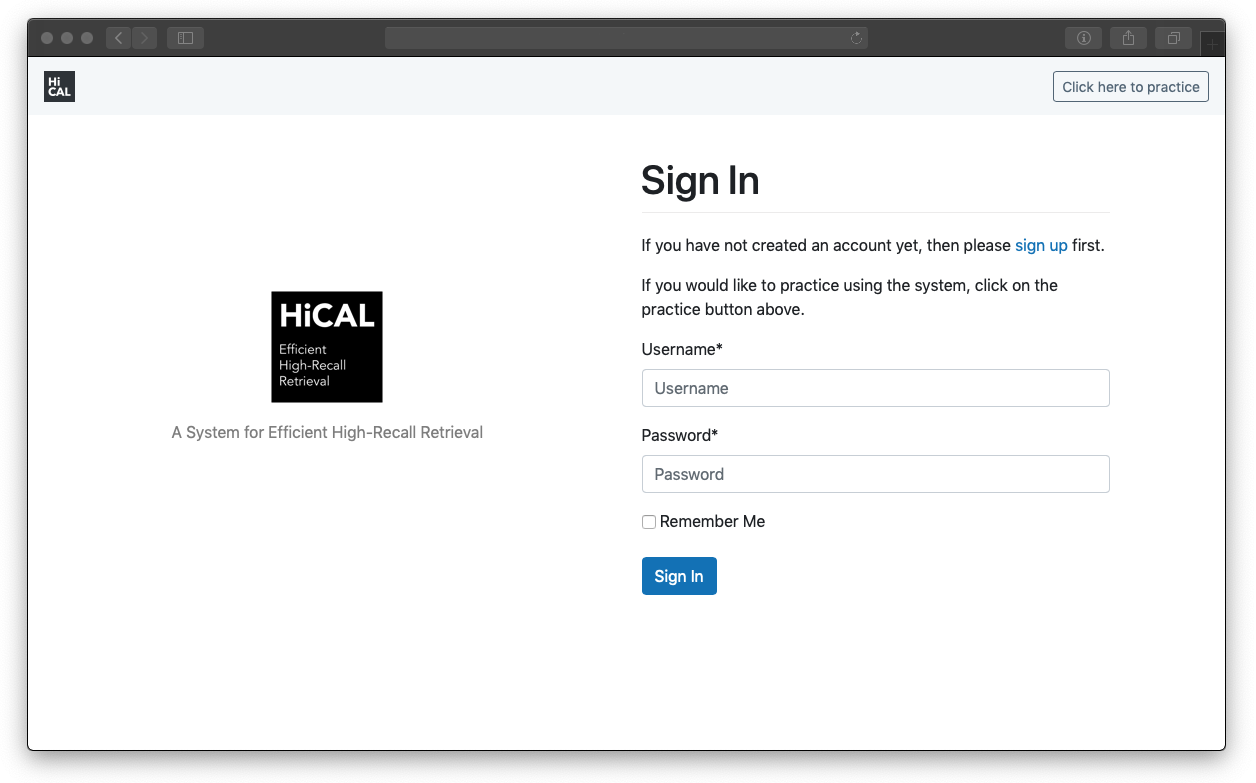
Want to find all relevant documents?
HiCAL is a system for efficient high-recall retrieval. The system allows retrieving and assessing relevant documents and provides high data processing performance and a user-friendly document assessment interface.
Installation
Requirements
The system is dockerized into different docker images. Make sure your machine has these installed
docker: Refer to this installation guide if you would like to install it on Ubuntu 16.04docker-compose
Corpus and How to Install
Before you start installing, you need to make sure your corpus is ready and in the right format. This step is necessary to be able run the system. We will work with a toy corpus from https://github.com/hical/sample-dataset
# Checkout the repo
git clone https://github.com/HiCAL/HiCAL.git
cd HiCAL
# Checkout the sample dataset
git clone https://github.com/hical/sample-dataset.git
cd sample-dataset
python process.py athome4_sample.tgz
# Create the data directory which is mounted to the docker containers
mkdir ../data
cp athome4_sample.tgz athome4_sample_para.tgz ../data/
cd ..
process.py is an example of how one might clean the corpus and generate excerpts. We will use the athome4_sample.tgz and the newly generated athome4_sample_para.tgz to generate document features.
# Build and access the shell from the cal container
docker-compose -f HiCAL.yml run cal bash
root@container-id:/# cd src && make corpus_parser
# Generate features
root@container-id:/# ./corpus_parser --in /data/athome4_sample.tgz --out /data/athome4_sample.bin --para-in /data/athome4_sample_para.tgz --para-out /data/athome4_para_sample.bin
# Exit the shell with Ctrl+D
We will now generate the document and paragraph files which will be showed to the assessors. Access and parsing logic for a corpus is decribed in the functions.py file. HiCAL by default supports the xml documents from the New York Times corpus. We have provided an alternative functions.py which works for athome4.
# Extract the tgz files
cd data
tar xvzf athome4_sample.tgz
mv athome4_test docs
tar xvzf athome4_sample_para.tgz
mv athome4_test para
cd ..
# Use the modified functions.py
cp sample-dataset/functions.py HiCALWeb/hicalweb/interfaces/DocumentSnippetEngine/functions.py
# We are all set! Lets fire up the containers
DOC_BIN=/data/athome4_sample.bin PARA_BIN=/data/athome4_para_sample.bin docker-compose -f HiCAL.yml up -d
# Visit localhost:9000
If you get a 502 Bad Gateway error, please wait few seconds while the containers finish processing.
Port 9001 and 9000 will be used by system. Make sure these ports are not being used by other applications in your machine. If you would like to change these ports, please read the configuration section below.
We strongly recommend installing via docker. If you would like to not use docker, please look at the documentation page for more details.
How to run
Once your docker images are up and running (you can verify by running docker-compose -f HiCAL.yml ps), open your browser to http://localhost:9000/. You should be able to access system's web interface. If you are still unable to view the web interface, try replacing http://localhost with the ip address of your docker machine (you can get the ip by running docker-machine ip)
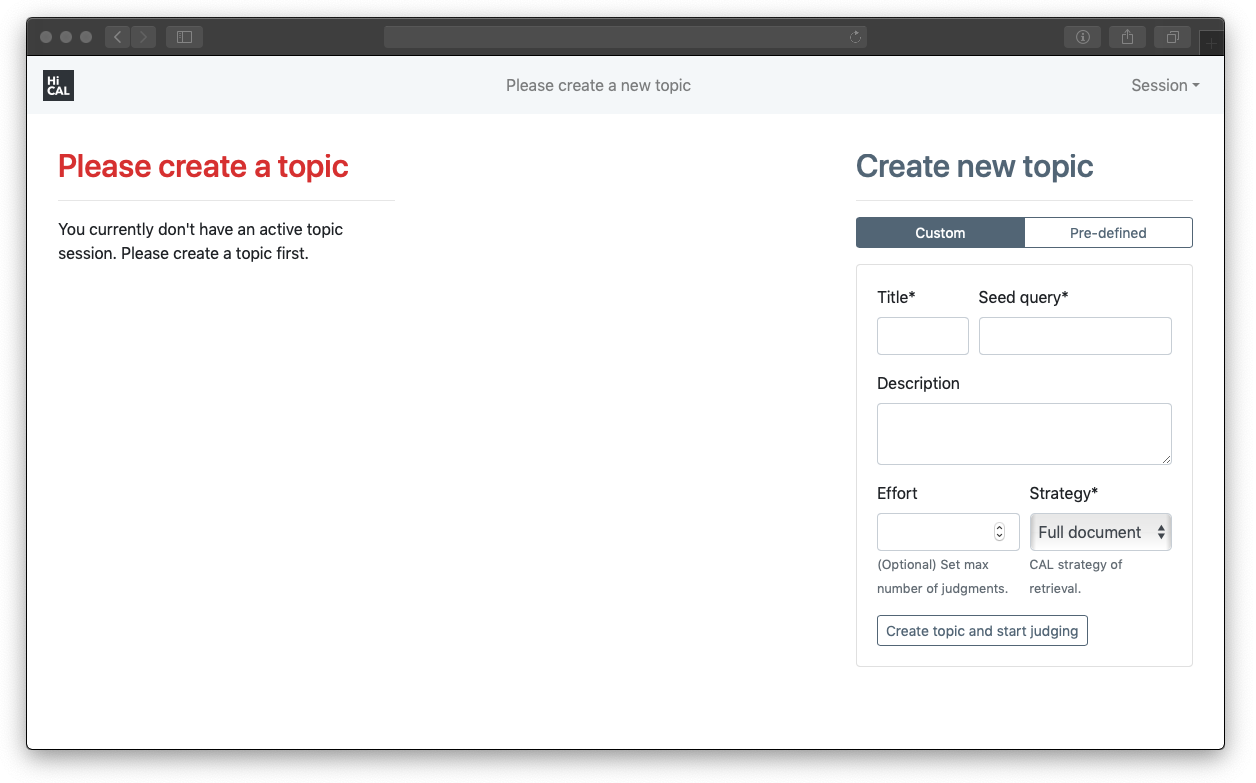
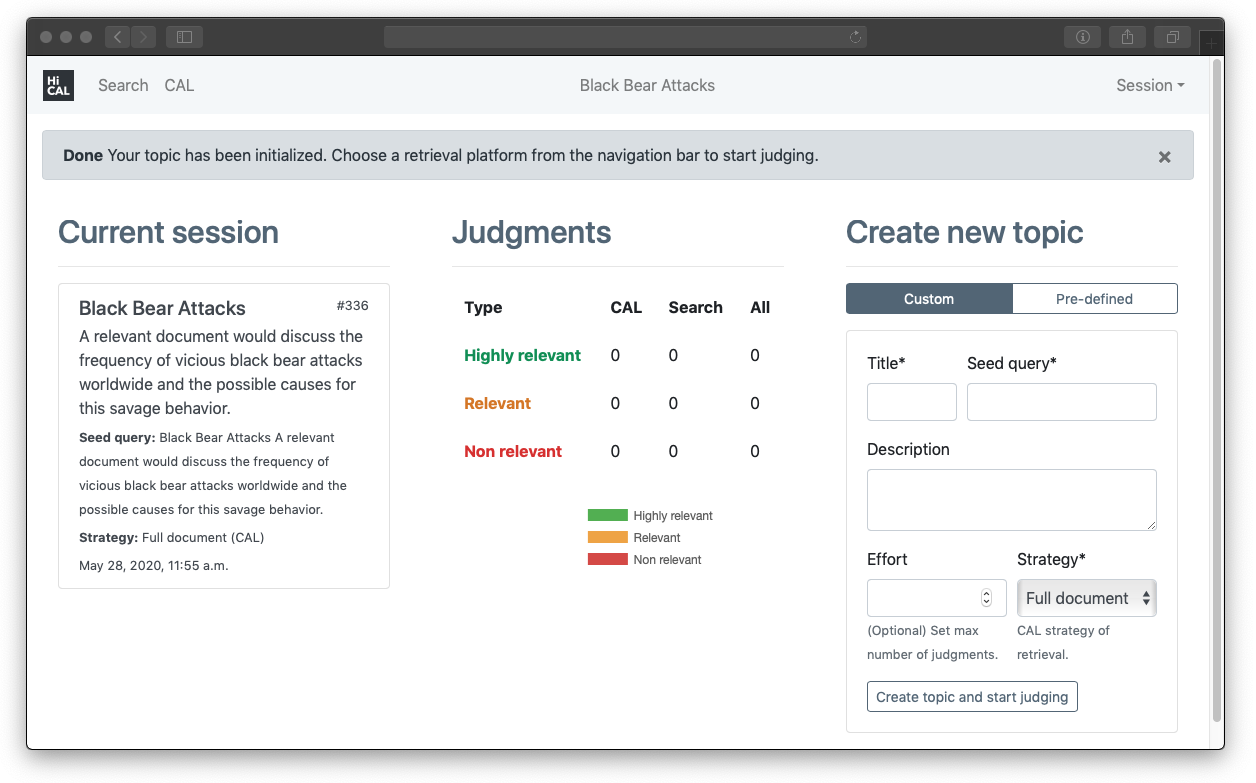
Configuration
Most of the configuration can be performed through these two files:
- config/nginx/nginx.conf :
-
This file controls the nginx server. By default, the CAL is accessed through port
9001and the web interface is accessed through port9000. These ports are exposed to the outside world by the docker (specified in HiCAL.yml). Our system uses the nginx instance to serve document and paragraphs to the web interface. - HiCAL.yml :
- CAL:
-
./datais mounted to the volume /data which is meant to be used the bmi_fcgi. Keep document features and related files over there. Modify command field if required. - nginx:
-
the container uses config/nginx/nginx.conf as the config. Make changes to the volumes as required.
Configuring Search
The system allows integration of a search engine. Any search engine can be integrated with minimal effort.
To integrate a search engine, please read the documentation.
Bugs, issues or feature requests?
Please report here.
LICENSE
